线程安全就是多线程访问某个数据时(一般是同时进行写操作),采用了加锁机制,当一个线程访问该类的某个数据时,进行保护,其他线程不能进行访问直到该线程读取完,其他线程才可使用。不会出现数据不一致或者数据污染。 线程不安全就是不提供数据访问保护,有可能出现多个线程先后更改数据造成所得到的数据是脏数据.下面就介绍一下iOS开发中的锁们.具体Demo请点击
目录 (按照锁的效率排列)
OSSpinLock
os_unfair_lock
dispatch_semaphore
pthread_mutex_t
NSLock
NSCondition
NSRecursiveLock
NSConditionLock
atomic
@synchronized
</b>
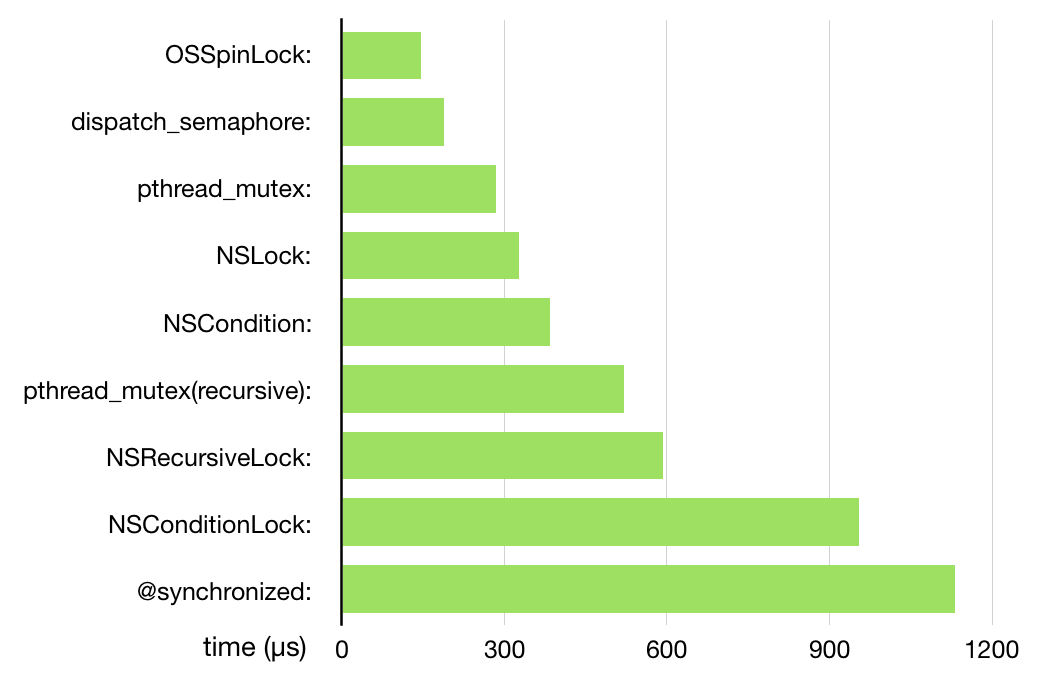
各种锁的效率对比图片:
自旋锁
OSSpinLock
由于自旋锁存在优先级反转问题(可查看YYKit作者的这篇文章 不再安全的 OSSpinLock),在iOS 10.0中被<os/lock.h>中的os_unfair_lock()取代. 优先级反转主要是因为高优先级线程始终会在低优先级线程前执行,一个线程不会受到比它更低优先级线程的干扰。这种线程调度算法会产生潜在的优先级反转问题,从而破坏了 spin lock.
1 | |
os_unfair_lock优化之后的 OSSpinLock
1 | |
dispatch_semaphore
一种可用来控制访问资源的数量的标识,设定了一个信号量,在线程访问之前,加上信号量的处理,则可告知系统按照我们指定的信号量数量来执行多个线程。
其实,这有点类似锁机制了,只不过信号量都是系统帮助我们处理了,我们只需要在执行线程之前,设定一个信号量值,并且在使用时,加上信号量处理方法就行了。
主要方法:
1 | |
semaphore.wait(timeout: DispatchTime.now() + 1)
作用:
- GCD控制并发数量的方法(NSOperation可以直接设置并发数)
- 信号量为 0: 等待, 型号量为1: 执行
应用:
1.做权限请求, 比如网络权限, 或者通讯获取权限等, 当用户同意网络权限之后信号量+1, 执行正常逻辑的代码
2.做网络请求的等待
3.控制并发数量
1 | |
pthread_mutex_t
C语言级别的锁,需引入头像文件#import
1 | |
PTHREAD_MUTEX_NORMAL 缺省类型,也就是普通锁。当一个线程加锁以后,其余请求锁的线程将形成一个等待队列,并在解锁后先进先出原则获得锁。
PTHREAD_MUTEX_ERRORCHECK 检错锁,如果同一个线程请求同一个锁,则返回 EDEADLK,否则与普通锁类型动作相同。这样就保证当不允许多次加锁时不会出现嵌套情况下的死锁。
PTHREAD_MUTEX_RECURSIVE 递归锁,允许同一个线程对同一个锁成功获得多次,并通过多次 unlock 解锁。
PTHREAD_MUTEX_DEFAULT 适应锁,动作最简单的锁类型,仅等待解锁后重新竞争,没有等待队列。
1 | |
NSLock
NSLock互斥锁 不能多次调用lock方法,会造成死锁
在Cocoa程序中NSLock中实现了一个简单的互斥锁。所有锁(包括NSLock)的接口实际都是通过NSLocking协议定义的,它定义了lock和unlock方法。你使用这些方法来获取和释放该锁。
NSLock类还增加了try()和 lock(before limit:) 方法。try() 视图获取一个锁,但是如果锁不可用的时候,它不会阻塞线程,相反,它只是返回NO。
1 | |
NSCondition
1 | |
NSRecursiveLock–递归锁
使用锁最容易犯的一个错误就是在递归或循环中造成死锁,在NSLock锁中,如果锁多次的lock,自己会被阻塞。
NSRecursiveLock实际上定义的是一个递归锁,这个锁可以被同一线程多次请求,而不会引起死锁。这主要是用在循环或递归操作中。我们先来看一个示例:
1 | |
这段代码是一个典型的死锁情况。在我们的线程中,testRecursiveLock是递归调用的。所以每次进入这个block时,都会去加一次锁,而从第二次开始,由于锁已经被使用了且没有解锁,所以它需要等待锁被解除,这样就导致了死锁,线程被阻塞住了。调试器中会输出
如下信息:
1 | |
在这种情况下,我们就可以使用NSRecursiveLock。它可以允许同一线程多次加锁,而不会造成死锁。递归锁会跟踪它被lock的次数。每次成功的lock都必须平衡调用unlock操作。只有所有达到这种平衡,锁最后才能被释放,以供其它线程使用。
所以,对上面的代码只需将
1 | |
改成:
1 | |
输出如下:
1 | |
NSRecursiveLock除了实现NSLocking协议的方法外,还提供了两个方法,分别如下:
1 | |
这两个方法都可以用于在多线程的情况下,去尝试请求一个递归锁,然后根据返回的布尔值,来做相应的处理。如下代码所示:
1 | |
在前面的代码中,我们又添加了一段代码,增加一个线程来获取递归锁。我们在第二个线程中尝试去获取递归锁,当然这种情况下是否能成功请求到锁, 要看第一个线程中的锁是否释放, 如果第一个线程并未释放锁, 那么第二个线程是无法获取到锁的.
另外,NSRecursiveLock还声明了一个name属性,如下:
1 | |
我们可以使用这个字符串来标识一个锁。Cocoa也会使用这个name作为错误描述信息的一部分。
NSConditionLock
NSConditionLock: 条件锁,一个线程获得了锁,其它线程等待。
lock() 表示获得锁,如果没有其他线程获得锁(不需要判断内部的condition) 那它能执行此行以下代码,如果已经有其他线程获得锁(可能是条件锁,或者无条件锁),则等待,直至其他线程解锁
lock(whenCondition: 条件A) 表示如果没有其他线程获得该锁,但是该锁内部的condition不等于A条件,它依然不能获得锁,仍然等待。如果内部的condition等于A条件,并且没有其他线程获得该锁,则进入代码区,同时设置它获得该锁,其他任何线程都将等待它代码的完成,直至它解锁。
unlock(withCondition:B条件) 表示释放锁,同时把内部的condition设置为B条件
1 | |
dispatch_barrier_async
在Swift4中, dispatchBarrier被废弃, 此功能合并到了DispatchWorkItem中的flags选项
注意:使用barrier时所有的workItem必须在同一个队列中, 不能使用globalQueue
1 | |
@synchronized
1)@synchronized关键字加锁 互斥锁,性能较差不推荐使用
1 | |
注意点
- 加锁的代码尽量少
- 添加的OC对象必须在多个线程中都是同一对象
- 优点是不需要显示创建锁对象,便可以实现锁的机制。
- @synchronized块会隐式的添加一个异常处理例程来保护代码,该处理例程会在异常抛出的时候自动释放互斥锁。所以如果不想让隐式的异常处理例程带来额外的开销,可以考虑使用该锁对象。
在 Swift 中它已经 (或者是暂时) 不存在了。其实 @synchronized 在幕后做的事情是调用了 objc_sync 中的 objc_sync_enter 和 objc_sync_exit 方法,并且加入了一些异常判断。因此,在 Swift 中,如果我们忽略掉那些异常的话,我们想要 lock 一个变量的话,可以这样写:
1 | |
属性的原子性
原子特性,简要来说,是针对多线程而设置的。Objective-C拥有两种原子特性,分别是atomic和nonatomic。
我们知道,如果使用多线程的话,有时会出现两个线程互相等待而导致的死锁现象。使用atomic特性,Objective-C可以防止这种线程互斥的情况发生,但是会造成一定的资源消耗。这个特性是默认的。
而如果使用nonatomic,就不会有这种阻止死锁的功能,但是如果我们确定不使用多线程的话,那么使用这个特性可以极大地改善应用性能。
相比之下,swift目前还不支持这些特性。如果我们要实现线程安全,似乎只能使用objc_sync_enter此类的方法,来保证属性的处理只有一个线程在进行。或者使用属性观察器来完成这些操作。
对于 let 声明的资源,永远是原子性的。 对于 var 声明的资源,是非原子性的,对其进行读写时,必须使用一定的手段,确保其值的正确性。
Swift多个线程同时对同一个属性进行写操作不是线程安全的, 即使是OC中属性声明为原子属性(atomic),也不是线程安全的.
1 | |
控制台输出会出现: a:B或者b:A, 那么说明对同一个属性进行写操作不是线程安全的
参考资料: